Technical overview
How Patient Matching Works
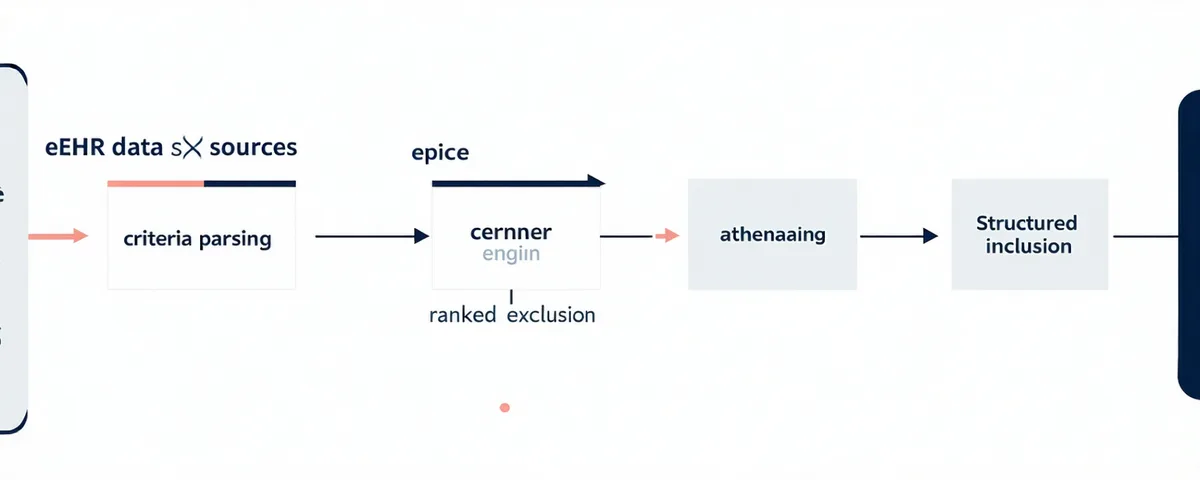
Four deterministic steps — from structured EHR data to ranked eligibility cohort — with data governance checkpoints at every stage.
EHR Data Ingestion
Cohortbridge connects to participating health system EHRs via FHIR R4 APIs. The connection is read-only. Cohortbridge never writes to the EHR and never retains identifiable patient records outside the health system's boundary.
Supported ingestion pathways: SMART on FHIR (Epic), FHIR R4 REST (Oracle Health/Cerner, Athenahealth), HL7 v2 structured export, CCD (Consolidated Clinical Document). For health systems with strict data residency requirements, Cohortbridge supports a read-only on-premise matching agent.
Protocol Criteria Parsing
Protocol inclusion and exclusion criteria are uploaded as structured or semi-structured input. Cohortbridge's criteria parsing layer converts free-text clinical criteria into structured eligibility logic: ICD-10 code ranges, lab value thresholds (with LOINC code mapping), diagnosis duration requirements, medication history exclusions, and demographic filters.
For common indication types, Cohortbridge maintains a pre-parsed criteria library that reduces setup time. Custom criteria require a one-time mapping review with the Cohortbridge clinical informatics team before the first match run.
Eligibility Engine
The eligibility engine runs the parsed criteria logic against the connected EHR population. Each patient record is evaluated against all inclusion and exclusion criteria. The engine returns an eligibility confidence score (0–100) based on: (a) how completely the patient record maps to required fields, and (b) how definitively each criterion is met or excluded.
Records with incomplete field coverage receive lower confidence scores but remain in the output with a field-completeness indicator — allowing the CRO team to decide whether targeted chart review for those records is warranted.
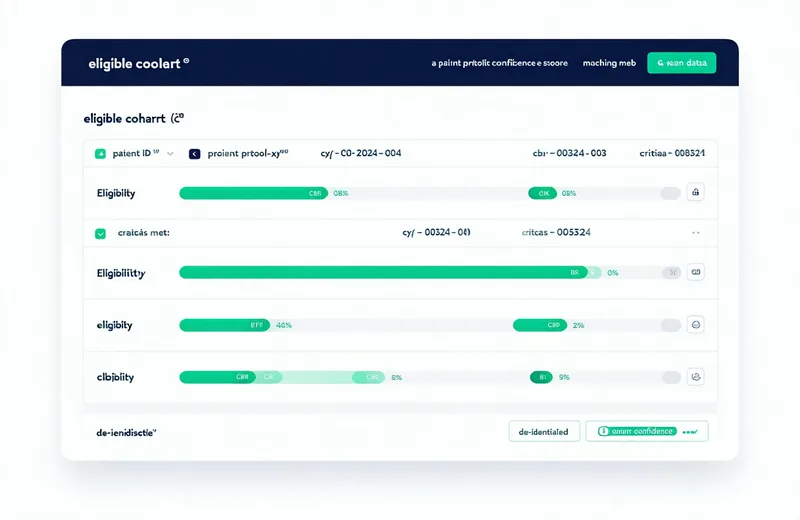
Ranked Cohort Output
The CRO feasibility team receives a ranked cohort list. Each entry contains a Cohortbridge-assigned de-identified reference ID, an eligibility confidence score, a criteria match breakdown (which criteria are met, which require confirmation), and a field completeness indicator. No patient names, MRNs, dates of birth, or other direct identifiers appear in the output.
The cohort output is used by the CRO team to estimate enrollment potential per site, prioritize sites for activation, and — after obtaining proper consent and IRB authorization — initiate direct patient outreach through the health system's clinical staff.
HIPAA safeguards at every step of the pipeline
Cohortbridge is designed with HIPAA administrative, technical, and physical safeguards throughout the matching pipeline — not as a post-hoc compliance layer.
Minimum Necessary Use
EHR queries are scoped to the minimum patient population and minimum field set required by the protocol's inclusion/exclusion criteria.
De-identification Before Output
All patient identifiers are removed before cohort data leaves the health system boundary. CRO teams receive cohort reference IDs, not patient records.
Audit Trail
Every query, criteria parse, and cohort output is logged with timestamp, user, and protocol association for sponsor and IRB audit purposes.
Connects to the EHR systems your sites already use
Cohortbridge supports FHIR R4-based integration with the major EHR platforms used by US health systems and academic medical centers. Implementation typically takes 4–6 weeks from EHR access agreement execution to first match run.
On-premise option available
Health systems with strict data residency requirements can deploy the Cohortbridge matching agent within their own infrastructure. Matching runs locally; only de-identified cohort IDs are returned to the CRO team. Patient data never leaves the health system network.
See the matching process with your protocol
We'll walk through a live de-identified match run using your trial's inclusion/exclusion criteria. Understand exactly how Cohortbridge would work for your specific indication before any commitment.